数据预处理—归一化(连续值和离散值)
归一化原因
1. 如果多个特征之间数值差异较大,那么收敛速度会很慢。如吴恩达老师在《机器学习》中给出的例子:
x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快 2. 在涉及到距离计算的模型中,若多个特征之间数值差异较大,那么数值小的特征对距离的影响则很小,这会造成精度的影响
归一化目的
1. 将数据按照一定的规则转变为(0,1)之间的数据; 2. 把有量纲表达式转变为无量纲表达式
连续值归一化常见方法
Max-Min
Xmin/Xmax分别对应数据集中最小、最大的数据,X是待归一化数据
0均值标准化(Z-Score)
其中x为某一具体分数,μ为平均数,σ为标准差。 Z值的量代表着原始分数和母体平均值之间的距离,是以标准差为单位计算。在原始分数低于平均值时Z则为负数,反之则为正数。
在距离度量计算相似性、PCA中使用第二种方法(Z-score standardization)会更好,参考Max-Min和Z-Score对比
对数函数法
主要用于数量级很大的场合###反正切函数 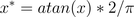
主要用于将角频率等变量转换到[-1,1]的范围
离散值归一化常见方法
One-Hot编码
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
例如:
1. 自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
2. 性别特征有三种特征值:男、女、其他
独热编码为:001,010,100
参考
http://blog.****.net/pipisorry/article/details/52247379
http://blog.****.net/pipisorry/article/details/61193868